


2. Information retrieval:
strumenti e strategie
4. Biblioteche e Opac
nel mondo
5. Biblioteche e Opac
in Italia
7. Le biblioteche
e gli Opac statunitensi
8. Opac specializzati,
archivi e musei
10. Banche dati: archivi
e host computer in Internet
11. Metarisorse generali
e informazioni per bibliotecari
Parte terza – Oltre i cataloghi: testi e banche dati
11. Metarisorse generali e informazioni per bibliotecari
Indici generali del World Wide Web
La ricerca di informazioni in Rete
L'invisible Web e i motori per la ricerca multimediale
I limiti: la crescita della Rete e il «pay for placement»
La nuova rotta di Altavista e le grandi acquisizioni
L’evoluzione dei motori, da A9 a Mooter
Aib-Web e altre risorse per bibliotecari
Liste, periodici e reference desk per bibliotecari
La tecnologia migliora, ma a fianco dell'invisible Web tradizionale se ne sviluppa un altro, ben più preoccupante, a causa della crescita di Internet e delle scelte strategiche e commerciali delle aziende che gestiscono i grandi motori di ricerca. Così una buona parte del World Wide Web risulta oggi di fatto irraggiungibile e quindi invisibile.
Nella primavera del 2000 erano stati diffusi i risultati di una ricerca di Inktomi <http://www.inktomi.com>, uno dei più importanti produttori di sistemi per motori di ricerca, condotta insieme al Nec research institute, secondo la quale sarebbero esistiti 5 o 6 miliardi di pagine Web, la maggior parte delle quali non veniva raggiunta dai motori di ricerca. E i motori di ricerca, ormai, non avrebbero avuto neppure più molta voglia di indicizzare proprio tutto: sempre secondo Inktomi, infatti, il 25% dei documenti era irrilevante e un altro 25% aveva interesse solo per un numero molto ristretto di persone. Il produttore californiano quindi si accontentava di mantenere un archivio con «solo» 1,6 miliardi di link. Successivamente, dalle stime di Oclc sulla crescita del numero dei siti Web <http://www.oclc.org/research/projects/archive/wcp/stats/size.htm>, sembrerebbe che le pagine in Rete avessero già superato i 9 miliardi alla fine del 2002. Oggi non esistono stime recenti sul numero complessivo delle pagine Web, che potrebbero aggirarsi intorno ai 10 miliardi, coperte solo per quattro quinti da Google (volendosi fidare dei dati non verificati forniti da Google stesso) e al massimo per metà dagli altri motori.
A fianco degli indici generali, però, molti motori mantengono altri indici più piccoli, dedicati a diverse zone geografiche, come l'Europa o il Giappone. L'obiettivo quindi non è più percorrere tutte le risorse esistenti in Rete, ma selezionare in questo mare magnum soltanto quelle che sono più interessanti per gli utenti, cercando di dare maggior peso alle informazioni locali.
È ancora grave anche il problema dei tempi di aggiornamento dei link: per Inktomi il tempo medio di aggiornamento era di tre mesi fino al 2000, un mese nel 2001 e due settimane nel 2002. Due settimane possono comunque essere un periodo troppo lungo per chi cerca, per esempio, informazioni legate ad avvenimenti di attualità o pubblicazioni molto recenti. Si pensi, inoltre, che nel maggio 2003, Greg Notess stimava in quattro settimane il tempo di aggiornamento medio di Inktomi stesso, in un mese quello di Google e di Alltheweb, in tre quello di Altavista e addirittura in sei e sette mesi quelli rispettivamente di Wisenut e Gigablast.
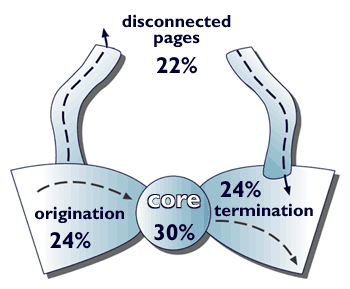
Figura 20. Il "papillon" dei Web individuato dalla ricerca di Ibm, Altavista e Compaq.
Non sono migliori le notizie che arrivano da un altro studio di cui si è parlato molto nella primavera del 2000, l'ultimo realizzato su vasta scala e pubblicato, condotto da Ibm, Altavista e Compaq. Secondo questa ricerca <http://www.almaden.ibm.com/cs/k53/www9.final> il Web sarebbe diviso in quattro regioni diverse, non così ben connesse tra loro come si era pensato. La mappa dei siti Web potrebbe essere rappresentata da un cravattino a farfalla.
In quella che è stata definita la teoria del «papillon», quattro sezioni rappresentano: un nucleo di siti molto connessi (il 30% del totale), un insieme di pagine «di origine» (24%), un insieme di pagine «di arrivo» (24%) e le restanti pagine «disconnesse» (22%).
Il nucleo centrale può essere navigato con facilità, grazie a un grande numero di collegamenti. La parte sinistra della farfalla contiene invece pagine che permettono di raggiungere il nucleo centrale ma che non sono raggiungibili da esso. Al contrario, la parte destra del cravattino può essere raggiunta facilmente dalla parte centrale ma non ha molti link che riportino ad essa. Le pagine disconnesse, infine, sono tagliate fuori dal nucleo centrale e sono collegate solo tra loro, in quella che potrebbe essere definita la periferia del Web. Dopo il 2000 non sono più state pubblicate ricerche complete e approfondite sulle caratteristiche morfologiche del Web, diventate costose e complesse per la continua crescita della Rete.
La situazione dell'information retrieval sul Web è stata complicata finora da una propensione sempre maggiore da parte dei gestori dei grandi motori per modelli commerciali di vario tipo definiti genericamente «pay for placement», secondo i quali un'azienda può pagare per garantirsi una buona posizione delle sue pagine Web nella lista ottenuta dalla ricerca con determinate parole chiave.
Queste tecniche, di vera e propria vendita al miglior offerente dei risultati delle ricerche, favoriscono i siti delle aziende commerciali più ricche e tendono a relegare nelle ultime posizioni tutti i siti non profit o comunque privi di finanziamenti, rendendoli, se non invisibili, difficilmente rintracciabili.
Non sempre motori e directories dichiarano apertamente la loro politica rispetto a queste soluzioni; per gli utenti, quindi, fare una scelta tra strumenti «buoni» e «cattivi» non è facile. Spesso si nota la chiara volontà di confondere le idee al navigatore: la già citata directory Looksmart, per esempio, era stata contestata perché presentava i risultati divisi nelle sezioni «Featured listing», «Directory topics» e «Reviewed Web sites», dove solo la seconda lista, la Directory topics, rappresentava un lavoro privo di aggiustamenti per le aziende paganti.
Contro tali pratiche si era schierato Ralph Nader, che a luglio del 2001 aveva chiesto alla Federal trade commission statunitense (Ftc) di intervenire legalmente contro diversi motori, per bloccare un fenomeno che era ed è diventato assimilabile alla pubblicità occulta.
Altre soluzioni sono meno drastiche, come il sistema Index connect proposto da Inktomi, e prevedono che, sempre a pagamento, le pagine di un sito vengano aggiornate nell'indice con una frequenza maggiore, senza però cambiare i criteri di rilevanza con cui vengono ordinati i risultati. Ancora più morbido è il sistema adottato da Google, che vende non i risultati ma solo dei banner pubblicitari che compaiono associati a certe parole di ricerca; per il momento i gestori di questo motore continuano a dichiarare che non si piegheranno alla logica del pay for placement.
È importante sottolineare che nessun motore, neppure Google, fornisce indicazioni complete e precise sui propri algoritmi di ranking. Il motivo è la necessità di contrastare lo «spamdexing», cioè quell'insieme di tecniche che i gestori dei siti Web adottano per ingannare gli spider e gli indexer dei motori e per ottenere quindi un buon piazzamento in corrispondenza del maggior numero possibile di parole chiave, anche per argomenti estranei al contenuto delle proprie pagine.
La situazione del «pay for», che era peggiorata in modo drastico nel corso del 2001, è in continua evoluzione. Le informazioni disponibili su quali tecniche vengono adottate dai principali motori di ricerca sono di solito pubblicate dal Search engine watch <http://searchenginewatch.com>. Per una breve panoramica sulle varie tipologie di pagamento possibili si veda l'articolo di Mariateresa Pesenti, Strumenti di ricerca: chi paga? in Esb forum <http://www.burioni.it/forum/pes-paga.htm>.